Thursday, November 09, 2006
Delta Specification
Delta is an XML-based language for describing changes to XML documents. A delta document (doc) contains a reference to a target XML doc, and a sequence of elements that describe “add” and “remove” operations to be applied to the target doc.
Delta makes it possible to describe changes without modifying the underlying doc. This allows a group of people to exchange changes efficiently, without exchanging the doc itself. Additionally, delta makes it possible to compare sets of independent changes, and merge delta operations as a way of combining multiple peoples’ work.
Increasingly, people are using XML as a means of formatting data to be exchanged between programs. Historically though, changes have been transmitted as updated versions of XML docs, and this places the burden on the receiving program to figure out what the changes are, by comparing versions. This approach results in lost information (i.e. the intermediate change steps), and it is inefficient when the docs become large.
Delta keeps change information out of the original doc, and organizes the changes in a sequence that corresponds to the order in which they are made. As such, a delta doc represents the recipe for how a set of changes is to be made, and thus, is distinct from the doc itself.
Figure 1 illustrates the relationships among the delta docs, the docs undergoing changes, and the software components required to process these docs. The delta doc has a dependency upon a separate XML doc that is being changed. Furthermore, the delta processor operates upon the delta doc in order to apply changes to the start doc, and produce an output (end) doc.
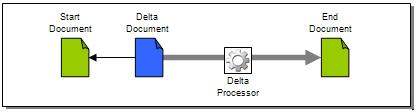
Figure 1: Delta Components
This specification describes the rules for creating valid delta docs, as well as the rules that delta processors must follow in applying change operations to a target doc.
Language Elements
<Delta> Element
The
Delta docs can optionally provide a date value by way of an <updated> element; using RFC 3339 format, to indicate when the delta doc was modified. This information is useful in determining the chronological order of multiple delta docs that reference the same target doc.
A delta doc must have a <start> or <end> element that specifies the URI to the target doc. This is followed by an <operations> element, which specifies the set of individual operations.
Following is a simple example of a delta doc that modifies an Atom feed, such that a new <entry> element is added after the first existing entry, and the <updated> element is removed from the <feed> element and replaced with a new one. Following the delta doc is the original feed doc.
<?xml version="1.0" encoding="utf-8"?>
<delta xmlns="http://www.delta.org/2006/Delta" version="0.1"
xmlns:xhtml="http://www.w3.org/1999/xhtml" xmlns:atom="http://www.w3.org/2005/Atom">
<updated>2006-03-31T11:42:55-05:00</updated>
<start>http://www.somewhere.com/atom1.xml</start>
<operations>
<add id="1">
<date>2006-03-31T11:42:51-05:00</date>
<path directive="after">//atom:feed/atom:entry[1]</path>
<value>
<atom:entry>
<atom:id>tag:intertwingly.net,2004:2180</atom:id>
<atom:link rel="alternate" />
<atom:title>Bridge Crossing Puzzle</atom:title>
<atom:summary>My daughter was given a puzzle.</atom:summary>
<atom:content type="xhtml">
<xhtml:div>
<xhtml:p>My daughter was given a puzzle.</xhtml:p>
</xhtml:div>
</atom:content>
<atom:updated>2006-03-31T11:42:54-05:00</atom:updated>
</atom:entry>
</value>
</add>
<remove id="2">
<date>2006-03-31T11:42:53-05:00</date>
<path>//atom:feed/atom:updated</path>
</remove>
<add id="3">
<date>2006-03-31T11:42:54-05:00</date>
<path directive="after">//atom:feed/*[3]</path>
<value>
<atom:updated>2006-03-31T11:42:54-05:00</atom:updated>
</value>
</add>
</operations>
</delta>
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en-US'>
<title>Example Feed</title>
<subtitle>Insert witty or insightful remark here</subtitle>
<link href='http://example.org/' />
<updated>2003-12-13T18:30:02Z</updated>
<author>
<name>John Doe</name>
</author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href='http://example.org/2003/12/13/atom03' />
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
</entry>
</feed>
<Operations> Element
The <operations> element contains an ordered list of “add” and “remove” operations. Each operation is represented by an <add> or <remove> element. Each of these elements must have an “id” attribute whose value is unique among its set of siblings. The id is used to determine the relative order in which the operations are to be applied. Optionally, one can include a child <date> element on each operation to specify an absolute point in time for the operation. This can be useful when a delta processor compares two or more separate delta documents, where the id alone does not provide enough information to determine the relative order in which the operations from separate delta docs occur.
“Add” and “remove” operations also contain a <path> element with an XPath value to determine where an operation should to be performed. Delta processors should evaluate the XPath, and use the resulting “found” element(s) and/or attribute(s) as the context in which to perform the operation.
It is very important to note that before applying an operation, a delta processor must apply all of the operations preceding the operation in the delta doc. This requirement assures that the state of the doc is valid for the XPath in the operation. In the case where a delta doc references an “end” doc instead, then the operations, starting from the end, back to the specific operation, must be applied in reverse order to undo the doc to the valid state for the specific operation.
<Add> Element
The XPath on an “add” operation must reference one or more “target” elements or attributes in the target doc. For “add” operations, the <path> element may also have a “directive” attribute that indicates where, relative to the target element/attribute, the value should be added. The values for the “directive” attribute are: “before”, “after”, and “child”, with “child” being the assumed value in the absence of a directive attribute.
<add id='1'>
<path directive="child">//xcal:iCalendar/xcal:vcalendar/xcal:vevent</path>
<value>
<ibmcal:summary>new summary</ibmcal:summary>
</value>
</add>
Example 1: Add a <summary> element as a child of an <xcal:vevent> element.
A path can also reference multiple elements, in which case the “add” operation is applied to each referenced element.
<path>//xcal:iCalendar/xcal:vcalendar/xcal:vevent/xcal:attendee[1 | 3 | 5]</path>
Example 2: An XPath that resolves to multiple elements.
An “add” operation can also have a <value> that is comprised of a sequence of child elements. In this case the sequence is added in the same manner as adding a single element. This approach makes it possible to combine a set of “add” operations where multiple children are being added to a single parent element.
Adding attributes poses a slightly different challenge. The XPath for an attribute-based “add” operation should reference the element(s) to which the attribute(s) should be added. Since an attribute is represented by a name and a value, delta uses an <attribute> element to encapsulate this information as a child element of the <value> element. A delta processor needs to unpack the attribute information from the <value> and create/add a new attribute to the XPath-referenced elements:
<add id="2">
<path>//xcal:iCalendar/xcal:vcalendar/xcal:vevent</path>
<value>
<attribute name="ibmcal:draft" value="true" />
</value>
</add>
Example 3: Add an @draft attribute to the <xcal:vevent> element.
To add an attribute, one can also specify an XPath to an existing attribute on an element, and then use the “directive” attribute on the <path> to indicate whether the attribute should be added “before” or “after” the referenced attribute.
<add id="3">
<path directive="after">//xcal:iCalendar/xcal:vcalendar/@version</path>
<value>
<attribute name="xcal:prodid" value="-//handcal//NONSGML 1.0//EN" />
</value>
</add>
Example 4: Add a @prodid attribute after the @version attribute on the <xcal:vcalendar> element.
<Remove> Element
“Remove” operations are easier to specify than “add” operations because the XPath simply references the element(s) and/or attribute(s) to remove. No “directive” is needed on the <path> element. As with “add” operations, one or more values can be removed in a single "remove" operation. Optionally, the removed values can be placed in the <value> element. However, in cases where a delta doc references an “end” state doc, the value on the “remove” operation is required to be saved, in order for a delta processor to be able to undo the “remove” operation and put the removed value back into the target doc.
<remove id="2">
<path>//xcal:iCalendar/xcal:vcalendar/xcal:vevent/xcal:attendee[
[@role="REQ-PARTICIPANT"] = "tuser1@dominoportal.com" | [@role="REQ-PARTICIPANT"] =
"tuser2@dominoportal.com" ]</path>
</remove>
Example 5: Remove two <xcal:attendee> elements where there’s a match on both the @role attribute, and the text value of the element.
In the case of removing an attribute, the entire attribute is removed, not just the value.
Delta Schema
This section contains the xsd representation of the delta schema:
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore"
xmlns:delta="http://www.delta.org/2006/Delta" attributeFormDefault="unqualified"
ecore:package="com.ibm.delta" elementFormDefault="qualified"
targetNamespace="http://www.delta.org/2006/Delta">
<xs:annotation>
<xs:documentation>This version of the Delta schema is based on version 0.1 of the
format specifications, found here
http://www.deltaweb.org/developers/delta-format-spec.html.</xs:documentation>
</xs:annotation>
<xs:import namespace="http://www.w3.org/XML/1998/namespace"
schemaLocation="http://www.w3.org/2001/03/xml.xsd" />
<xs:annotation>
<xs:documentation>A Delta document may have one root element:
delta</xs:documentation>
</xs:annotation>
<xs:element name="delta" type="delta:deltaType" />
<xs:complexType ecore:name="Delta" name="deltaType">
<xs:choice maxOccurs="unbounded" minOccurs="2">
<xs:element maxOccurs="1" minOccurs="0" name="updated" type="delta:dateTimeType" />
<xs:group maxOccurs="1" minOccurs="1" ref="delta:baseGroup" />
<xs:element maxOccurs="1" minOccurs="1" name="operations"
type="delta:operationsType">
<xs:unique name="operationId">
<xs:selector xpath="delta:operationType" />
<xs:field xpath="@id" />
</xs:unique>
</xs:element>
<xs:any maxOccurs="unbounded" minOccurs="0" namespace="##other"
processContents="lax" />
</xs:choice>
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:complexType>
<xs:group name="baseGroup">
<xs:choice>
<xs:element maxOccurs="1" minOccurs="0" name="start" type="delta:uriType" />
<xs:element maxOccurs="1" minOccurs="0" name="end" type="delta:uriType" />
</xs:choice>
</xs:group>
<xs:complexType ecore:name="URI" name="uriType">
<xs:simpleContent>
<xs:extension base="xs:anyURI">
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType ecore:name="Operations" name="operationsType">
<xs:choice maxOccurs="unbounded" minOccurs="1">
<xs:element maxOccurs="unbounded" minOccurs="0" name="add"
type="delta:operationType" />
<xs:element maxOccurs="unbounded" minOccurs="0" name="remove"
type="delta:operationType" />
</xs:choice>
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:complexType>
<xs:complexType ecore:name="Operation" name="operationType">
<xs:choice maxOccurs="unbounded" minOccurs="3">
<xs:element maxOccurs="1" minOccurs="1" name="date" type="delta:dateTimeType" />
<xs:element maxOccurs="1" minOccurs="1" name="path" type="delta:xPathType" />
<xs:element maxOccurs="1" minOccurs="1" name="value" type="delta:contentType" />
<xs:any namespace="##other" processContents="lax" />
</xs:choice>
<xs:attribute name="id" type="xs:positiveInteger" />
<xs:attribute name="family" type="xs:string" />
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:complexType>
<xs:complexType ecore:name="DateTime" name="dateTimeType">
<xs:simpleContent>
<xs:extension base="delta:iso8601dateTime">
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="iso8601dateTime">
<xs:union memberTypes="xs:dateTime xs:date xs:gYearMonth xs:gYear" />
</xs:simpleType>
<xs:complexType name="xPathType">
<xs:annotation>
<xs:documentation>A subset of XPath expressions for use in
selectors</xs:documentation>
<xs:documentation>A utility type, not for public use</xs:documentation>
</xs:annotation>
<xs:simpleContent>
<xs:extension base="delta:xPathTypeSimple">
<xs:attribute name="directive">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="before" />
<xs:enumeration value="after" />
<xs:enumeration value="child" />
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="xPathTypeSimple">
<xs:annotation>
<xs:documentation>A subset of XPath expressions for use in
selectors</xs:documentation>
<xs:documentation>A utility type, not for public use</xs:documentation>
</xs:annotation>
<xs:restriction base="xs:token">
<xs:annotation>
<xs:documentation>The following pattern is intended to allow XPath expressions
per the following EBNF: Selector ::= Path ( '|' Path )* Path ::= ('.//')? Step (
'/' Step )* Step ::= '.' | NameTest NameTest ::= QName | '*' | NCName ':' '*'
child:: is also allowed</xs:documentation>
</xs:annotation>
<xs:pattern
value="(\.//)?(((child::)?((\i\c*:)?(\i\c*|\*)))|\.)(/(((child::)?((\i\c*:)?(\i\c*|\*)))|\.))*(\|(\.//)?(((child::)?((\i\c*:)?(\i\c*|\*)))|\.)(/(((child::)?((\i\c*:)?(\i\c*|\*)))|\.))*)*" />
</xs:restriction>
</xs:simpleType>
<xs:complexType ecore:name="Content" mixed="true" name="contentType">
<xs:sequence>
<xs:any maxOccurs="unbounded" minOccurs="0" namespace="##other"
processContents="lax" />
</xs:sequence>
<xs:attribute name="src" type="xs:anyURI" use="optional" />
<xs:attributeGroup ref="delta:commonAttributes" />
</xs:complexType>
<xs:attributeGroup name="commonAttributes">
<xs:attribute ref="xml:base" />
<xs:attribute ref="xml:lang" />
<xs:anyAttribute namespace="##other" processContents="lax" />
</xs:attributeGroup>
</xs:schema>
Monday, April 03, 2006
The Delta Web
I’ve started a new project called “the delta web”. The idea is to define a markup language called "delta" for describing changes to Web-based documents such as Atom feeds. Delta lets you capture the notion of “change over time” or “work done” to content on the Web.
The motivation for delta is that there’s no simple way to describe how things change on the Web. I know that’s sort of a generalization. However, people create documents and publish them to URI’s, and then, when they change these documents, they usually just overwrite the originals, or create new versions with new URI’s. To see what’s changed, others have to compare versions to find “diffs”, or else look for time stamps within documents to get hints on when individual entities were added or removed.
Delta provides a new way for people to create standalone documents that explicitly describe changes to Web documents. It’s different from Microsoft's approach called SSE (Simple Shared Extensions to RSS), in that delta captures and stores change descriptions in their own documents, rather than being extensions to existing Web documents. More on how delta works later…
Simplicity is a key characteristic of delta. Delta is a markup language for describing changes. It is not a protocol or API, or a set of rules describing what to do with delta documents. Certainly, the delta web project will strive to explore different usage scenarios, but it's not about defining how people should collaborate in creating, or otherwise using delta documents.
One of the practical applications of delta is describing changes to feeds. People can create delta documents to describe changes to their feeds; so that others can see what changed explicitly. People can also create chains of deltas, each referencing the preceding delta, or they can stick to their habits of creating versions of feed documents, and augmenting this practice by using deltas to describe the changes to each version.
2) Core Concepts
Let’s say an application makes a set of changes to a Web-based XML document. Normally, such an application would store the result of these changes as a new version of the document, and notify others of the changes. Delta makes it possible for such an application to record the descriptions of the changes as they occur, and save them in the form of a delta document.
Some might say that delta provides redundant information, given the presence of old and new versions of the changed document. This isn’t quite true. A delta document describes when and how each of the changes was made. With a delta, an application can reapply changes, or a subset of changes, or can combine the elements of multiple deltas to create new deltas. This isn’t possible if all an application has to work with are discrete versions of documents made at different points in time.

A delta document referencing a start document.
Using an update mechanism, one can derive an end document using a delta.
In order to get things started, I've created a "strawman" XML schema for delta, and have provided an example (see below). A delta document contains a sequence of “add” and “remove” operations, in addition to a reference to a “start” or “end” document. Each delta operation has a precise date/time stamp, as well as an XPath reference to a location in the document, and an ability to hold a copy or reference to the value in question. An application can process a delta document by applying the set of changes in “forward” manner to a referenced “start” document, or in “reverse” manner to a referenced “end” document.
Since the application of delta operations changes the state of the referenced document, each operation is understood to be meaningful in the context of all preceding delta operations having been applied. This is important because, for example, a change operation may add an XML element to a document, and the next operation may reference a portion of this just-added element. Without having processed the sequence of change ops prior to a particular operation, the context, or state, of the document is not necessarily valid for that operation.
An update mechanism can apply a set of changes specified in a delta document to the start/end document, to produce a new updated document. People have the freedom of creating an updated document, and then discarding one or both of the original and the delta document. However, this results in a loss of information, namely the work that produced the updated document. Even if the original document and updated document are saved, and the delta document is discarded, the set of changes cannot be accurately derived, since there are many ways in which a set of changes can produce the same result. The only way to preserve the history of changes is by keeping the delta documents, and the original documents that they reference. Keep in mind that there are potentially many ways of preserving delta documents. One extreme approach is to keep a single monster-sized delta document versus a sequence of delta and intermediate documents. This raises the classic trade off between processing versus memory resources.
Some advantages of the delta markup language are as follows:
- Able to non-intrusively describe changes to any XML document, including those governed by schemas that do not allow extensions,
- Allows changes to be described without bloating the original data, or corrupting the context of the original data by inter-mixing change data with the underlying data,
- Is flexible enough to allow users to decide if and when they want to store deltas or process deltas and store document versions instead.
Some of the things that delta explicitly does not address:
- The rules for how one merges two delta documents that reference the same start/end document,
- The rules for how one applies delta operations in one delta to another delta that references a different start/end document,
- The rules for determining if conflicts exist among deltas, as well as how conflicts are to be resolved.
3) Example
The example involves an Atom feed located at a fictitious web site at the URI: http://www.somewhere.com/atom1.xml. For now, we’ll restrict the discussion to “forward” processing on “start” documents, rather than “reverse” processing on “end” documents.
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en-US'>
<title>Example Feed</title>
<subtitle>Insert witty or insightful remark here</subtitle>
<link href='http://example.org/' />
<updated>2003-12-13T18:30:02Z</updated>
<author>
<name>John Doe</name>
</author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href='http://example.org/2003/12/13/atom03' />
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
</entry>
</feed>
Document: atom1.xml
The change in question is simple. We want to add an <entry> element and change the <updated> element. The delta document representing these changes appears as follows, and we’ll give it the fictitious URI: http://www.somewhere.com/delta1.xml.
<?xml version="1.0" encoding="utf-8"?>
<delta xmlns='http://www.delta.org/2006/Delta' version='0.1'
xmlns:xhtml='http://www.w3.org/1999/xhtml'
xmlns:atom='http://www.w3.org/2005/Atom'>
<updated>2006-03-31T11:42:55-05:00</updated>
<start>http://www.somewhere.com/atom1.xml</start>
<operations>
<add id='1'>
<date>2006-03-31T11:42:54-05:00</date>
<path>//atom:feed/atom:entry[2]</path>
<value>
<atom:entry>
<atom:id>tag:intertwingly.net,2004:2180</atom:id>
<atom:link rel='alternate' />
<atom:title>Bridge Crossing Puzzle</atom:title>
<atom:summary>My daughter was given a puzzle.</atom:summary>
<atom:content type='xhtml'>
<xhtml:div>
<xhtml:p>My daughter was given a puzzle as extra credit.</xhtml:p>
</xhtml:div>
</atom:content>
<atom:updated>2006-03-31T11:42:54-05:00</atom:updated>
</atom:entry>
</value>
</add>
<remove id='2'>
<date>2006-03-31T11:42:53-05:00</date>
<path>//atom:feed/atom:updated</path>
</remove>
<add id='3'>
<date>2006-03-31T11:42:54-05:00</date>
<path>//atom:feed/*[4]</path>
<value>
<atom:updated>2006-03-31T11:42:54-05:00</atom:updated>
</value>
</add>
</operations>
</delta>
Document: delta1.xml
The <delta> element contains an <operations> element that contains a sequence of <add> and <remove> elements. These <add> and <remove> elements specify operations that are to be applied to the “start” document, as identified by the <start> element. The <start> element must have a valid URI format, but it can also be missing, indicating that the operations are to be applied to an empty document. The order of the sequence of <add> and <remove> elements corresponds to the order of operations. Each <add> and <remove> element has an “id” attribute that must be unique within the context of the parent <operations> element. The value of an id attribute does not necessarily have to be a valid URI, nor does it have to be globally unique by way of a mechanism such as “tag” URI format (RFC 4151), for example. This is because an id is valid only in the context of the sequence of operations specified by the enclosing delta.
For “remove” operations, we need to reference the path to the instance of the object in the start document that's being removed. The term object refers to element and/or attribute, because initially we'll focus on XML representations of start documents. For an element being removed, the path is an identifier to the instance of the element, and for an attribute, the path is an identifier specifying both the name of the attribute, and a particular element instance. It’s possible to specify a path that resolves to multiple object instances, in which case, all of them are operated upon. The language for specifying paths to elements and attributes is XPath, although the specification could easily allow other languages.
When an element is removed, the portion from, including the start tag, up to, including the end tag, is removed. For an attribute, the name and value are removed from the element. If a user wants to remove just the value of an attribute or change its value to a new value, this is accomplished by first removing the attribute, and then adding it with a null or different value. The goal is to keep the nature of “remove” operations consistent according to the KISS principle. Here, removal corresponds to complete eradication of the data, including its metadata.
For “add” operations, we need to reference the location in the start document where an object instance is to be added. For element locations, this is the path to an element instance, in addition to the position within that element’s child elements, if the element supports multiple values. The following illustrates a reference to the first <entry> element in a <feed> element, and furthermore, the second position among the <entry> element's children: /feed/entry[1]/*[2].
For attribute locations, we reference the name of the attribute in a specific instance of an element. Finally, for add operations, we include the value that is added, as the content of a <value> element. The value can be specified explicitly, or alternatively, as a reference to a block of data that resides in an external document, which is identified by a URI and a path to the object’s instance. For now, we'll focus on specifying values explicitly, in-line, as either a list of one or more elements, or as a text value suitable for XML attributes.
Both <add> and <remove> elements have a child <date> element specified in RFC 3339 format. Dates are not critical in determining the order in which to process a sequence of operations, but they are critical when comparing the operations in multiple delta documents that reference the same start document.
The following illustrates the new document that is produced by applying the changes specified by our example delta document.
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en-US'>
<title>Example Feed</title>
<subtitle>Insert witty or insightful remark here</subtitle>
<link href='http://example.org/' />
<updated>2006-03-31T11:42:54-05:00</updated>
<author>
<name>John Doe</name>
</author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href='http://example.org/2003/12/13/atom03' />
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2006-03-31T11:42:54-05:00</updated>
<summary>Some text.</summary>
</entry>
<entry>
<id>tag:intertwingly.net,2004:2180</id>
<link href='http://www.intertwingly.net/blog/2006/03/31/Bridge-Crossing-Puzzle' rel='alternate' />
<title>Bridge Crossing Puzzle</title>
<summary>My daughter was given a puzzle.</summary>
<content type='xhtml'>
<div xmlns='http://www.w3.org/1999/xhtml'>
<p>My daughter was given a puzzle as extra credit.</p>
</div>
</content>
<updated>2006-03-31T11:42:54-05:00</updated>
</entry>
</feed>
Document: atom2.xml
4) Collaboration
The simplest form of collaboration with delta documents involves merging two delta documents that reference the same start document. A merging mechanism needs to perform a chronology-based interleaving of the operations in each delta to form a single delta. During this process, the mechanism must detect if each operation has become invalid due to the merge. This happens if an operation’s path into the start document cannot be resolved, assuming that preceding delta operations have been applied to the start document. Finally, this merge mechanism must assign new ids to the merged operation elements. If the mechanism detects an invalid operation, it should throw an exception.
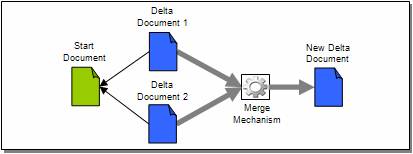
Merging Delta Documents that reference the same Start Document
The next level of collaboration involves applying operations from one delta document to another, in the case where the two start documents are different. Here, the challenge is to decipher the meaning of each “to-be-applied” operation in the context of the new start document. This is different from merging, where the start documents are the same. Each operation must first be examined in the context of its own start document, and then the merge mechanism must determine if it’s possible to create a new operation in the new delta document that has an equivalent meaning.
It’s possible for an operation in the first delta document to have a reference to a start document object that makes no sense in the context of the new start document. If this is the case, then the merge mechanism should throw an exception.

Applying a set delta operations from one delta to another, with different start documents
5) Additional Functionality
So far, we’ve only allowed delta documents to reference start documents. Next, we introduce “extension” references, which allow a delta document to extend, by continuation, the operations of another delta document. A delta document that specifies an extension does not need to specify a start document, since the start document is the same as the one specified in the referenced delta.
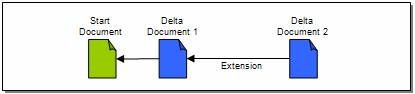
A second delta document extends a first delta document
An <extends> element specifies a URI that references a delta document that’s being extended. The operations in the extending delta are assumed to follow those in the delta being extended. Following is an example of a delta document that extends the delta shown earlier for our Atom feed start document.
<?xml version="1.0"?>
<delta xmlns='http://www.delta.org/2006/Delta' version='0.1'>
<updated>2006-04-01T11:42:55-05:00</updated>
<extends>http://www.somewhere.com/delta1.xml</extends>
<operations></operations>
</delta>
A delta document that extends another delta document.
Earlier, we saw that the ids on operations must be unique only in the context of the <operations> element of a delta. This means that ids on operations in an extension delta can potentially be the same as ids in the referenced delta document. This is OK, because the notion of “id” in a global sense is the combination of the URI of each delta document, followed by the local id used by the operation. The URI makes these operation ids unique in the global context.
A delta document followed by a chain of extension delta documents is logically equivalent to a single delta document. In other words, one could process the chain of deltas, including the root delta that points to the start document, and produce a single delta document that includes all of the operations from the individual extension deltas. This means that the merge and apply mechanisms described in the previous section apply to a chain of extension deltas in the same manner as they apply to a single delta document.
6) For Further Thought
6.1) Linked Operations
For now, delta supports only the two primitive operations, “add” and “remove”, in order to satisfy the KISS principle. It’s possible to consider expanding upon these operations in order to support “copy/paste” and “cut/paste”.
In order to specify a “copy/paste” operation, a user would effectively need the ability to specify an “add” operation that would include an additional reference to a “from” location in the start document. This location would be a place where the data would be copied from, as opposed to the “add” operation getting its data from its <value> element.
In order to specify a “cut/paste” operation, a user would need the ability to use a pair of “remove” and “add” operations, whereby the “add” operation would reference a “from” location that coincided with the path specified in the “remove” operation. In other words, the data being removed via the “remove” operation would be the same data that’s added by the “add” operation, but in a different place.
Having a “from” location property on an “add” operation would also enable a set of “add” operations to put copies of the same block of data in multiple places. A first “add” operation would place the data at a location specified by its <path> element, and subsequent “add” operations would reference the location of the added data as the “from” source for its own data. Alternatively, one could use a single “add” operation with an XPath value that resolved to multiple locations.
6.2) Cross-Delta Operations
With the linking capability specified in the previous section, by way of the proposed “from” reference, it’s conceivable that a delta operation could contain a “from” reference to a location outside the start document. This would allow a delta operation to perform a “copy” from a document other than the start document, followed by a “paste” into the start document.
6.3) Nested Operations
The concept of operation nesting would involve allowing a new <operation> element to enclose a list of child operations. This would allow processors to identify groups of related operations by a common id. For example, one could enclose a set of <add> elements with an <operation> element, and give the <operation>element an “id” attribute.
6.4) Multiple Deltas in a Delta Document
There might be times when a single delta document would benefit by being able to contain multiple <delta> elements. This would allow a single delta document to specify changes for a number of start documents, since each <delta> element would be free to specify its own start document. In order to enable this, we would need to define a <deltaset> element that would enclose some number of <delta> elements, and reside at the root of a delta document. This has ramifications on referencing that would need to be addressed.
6.5) Roll-forward and Roll-back Processing
As we mentioned previously, delta supports both roll-forward and roll-back processing. This section describes the requirements to support these scenarios in more detail.
By supporting the <value> element in the “remove” operation, it would be possible to add support for “roll-back” processing in addition to the “roll-forward” processing we’ve already discussed. In order to perform “roll-back” processing, there would have to be an additional <end> element as well as the <start> element, in order to hold a URI reference to the final finished, or “end-state” document. The idea would be that the delta operations could be processed in the forward chronological order against the referenced start document (as we’ve discussed), or they could be processed in reverse chronological order against the end document, to produce the start document. With this dual processing mechanism in place, one could create a “one sided” delta document that would either reference only a start or end document, or a “two sided” delta document that would reference both a start and end document.
The reason we’d need to store a value in the <value> element for “remove” operations, is that in order to perform the opposite of the "remove" operation against the end document, the processor would have to be able to get the removed element from the delta "remove" operation and stick it back into the end document. With one-sided delta documents, either all the “add” or “remove” operations would all have to store values. In the two-sided case, both the “add” and “remove” operations would have to store values.
7) References
I used a number of references to research this project. The following list is far from complete, but indicates some of the areas that I looked into.
- Simple Sharing Extensions for RSS and OPML
http://msdn.microsoft.com/xml/rss/sse/ - Atom Publishing Protocol
http://atompub.org/2005/07/11/draft-ietf-atompub-format-10.html - Code Merging Algorithms – RevCtrl WiKi
http://revctrl.org/FrontPage - Criss-Cross Merge Issues
http://www.gelato.unsw.edu.au/archives/git/0504/2279.html - Delta: an ontology for the distribution of differences between RDF graphs
http://www.w3.org/DesignIssues/Diff - DeltaXML – Diff/Merge for XML Documents
http://www.deltaxml.com/products/core/index.html - Wikipedia change visualization applications – Jon Udel commentary
http://weblog.infoworld.com/udell/2005/06/24.html - Phil Stanhope – Adesso Systems – Some observations on SSE
http://componentry.com/blogs/phil/archives/000164.html
Thursday, March 30, 2006
Disclaimer
Wednesday, March 29, 2006
First Post
![]()